


前言
JavaScript中的变量是松散类型的,没有规则定义它必须包含什么数据类型,它的值和数据类型在执行期间是可以改变的。
这样的设计规则很强大,但是也会引发不少的问题,比如我们本文即将要讨论的作用域与闭包,欢迎各位感兴趣的开发者阅读本文。
原理解析
理解作用域与闭包之前,我们需要先来深入解析下变量。
变量的原始值与引用值
变量可以存储两种不同类型的数据:原始值与引用值
- 用 基础包装类型 创建的值就是原始值
- 用 引用类型 创建的值就是引用值
我们来看下基础包装类型与引用类型都有什么:
在把一个值赋给变量时,JavaScript引擎必须确定这个值是 原始值 还是 引用值 :
- 保存 原始值 的变量是按值访问的,它保存在栈内存里。
- 保存 引用值 的变量是按引用访问的,它保存在堆内存里。
引用值就是保存在内存中的对象,JavaScript不允许直接访问内存位置,因此不能直接操作对象所在的内存空间。
在操作对象时,实际操作的是该对象的引用,所以保存引用值的变量是按引用访问的。
属性的操作
原始值和引用值的定义方式很类似,都是创建一个变量,然后给它赋值。
不过,在变量保存了这个值之后,可以对这个值做什么,则有着很大的区别。
- 引用值可以添加、修改、删除其属性和方法
- 原始值不能有属性与方法,只能修改其值本身
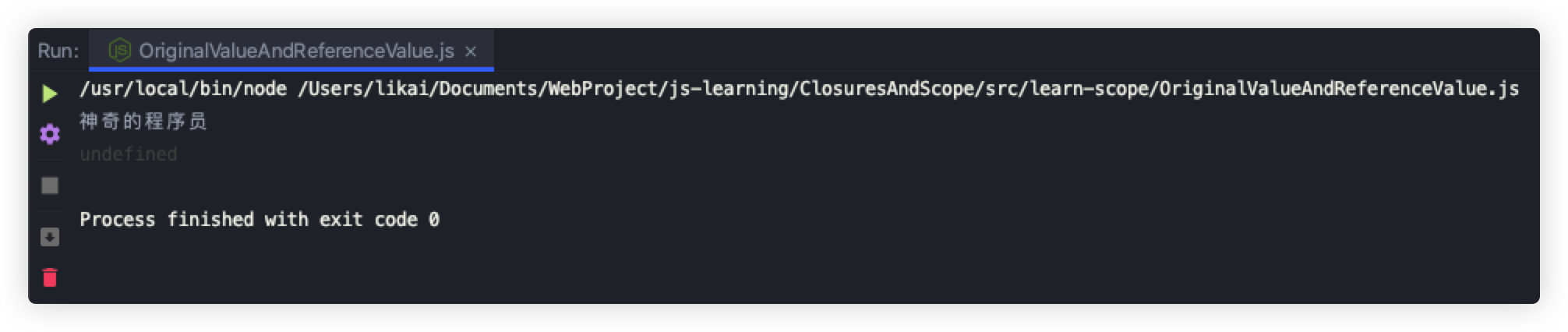
接下来,我们举个例子来验证下:
let person = {};
person.name = "神奇的程序员";
console.log(person.name); // 神奇的程序员
let person1 = "";
person1.name = "神奇的程序员";
console.log(person1.name); // undefined
上述代码中:
- 我们创建了一个名为
person的空对象,它是引用值 - 随后,给
person添加name属性并赋值 - 随后,打印
person.name,和预想一样,会得到正确的结果 - 紧接着,我们创建了一个名为
person1的空字符串,它是原始值 - 随后,我们给
person1添加name属性并赋值 - 最后,打印
person1.name,值为undefined
执行结果如下:
注意⚠️:当我们使用基础包装类型来创建变量时,得到的值是对象,它是引用值,可以添加属性和方法。例如:
let person2 = new String(""); person2.name = "神奇的程序员"; console.log(person2.name);
值的复制
我们将一个变量的值复制到另一个变量时,JS引擎在处理原始值与引用值的时候也是不相同的,接下来我们就来具体分析下。
- 复制原始值时,它的值会被复制到新变量的位置。
- 复制引用值时,它的指针会被复制到新变量的位置。
我们通过一个例子来讲解下:
let age = 20;
let tomAge = age;
let obj = {};
let tomObj = obj;
obj.name = "tom";
console.log(tomObj.name); // tom
上述代码中:
- 我们创建了一个变量,命名为
age,赋值为20,它是一个原始值 - 随后,我们创建了一个名为
tomAge的变量,将其赋值为age。 - 紧接着,我们创建了一个空对象,命名为
obj。 - 随后,我们创建了名为
tomObj的对象,将其赋值为obj。 - 随后,我们给
obj添加了name属性,赋值为tom。 - 最后,我们打印
tomObj.name,发现值为tom。
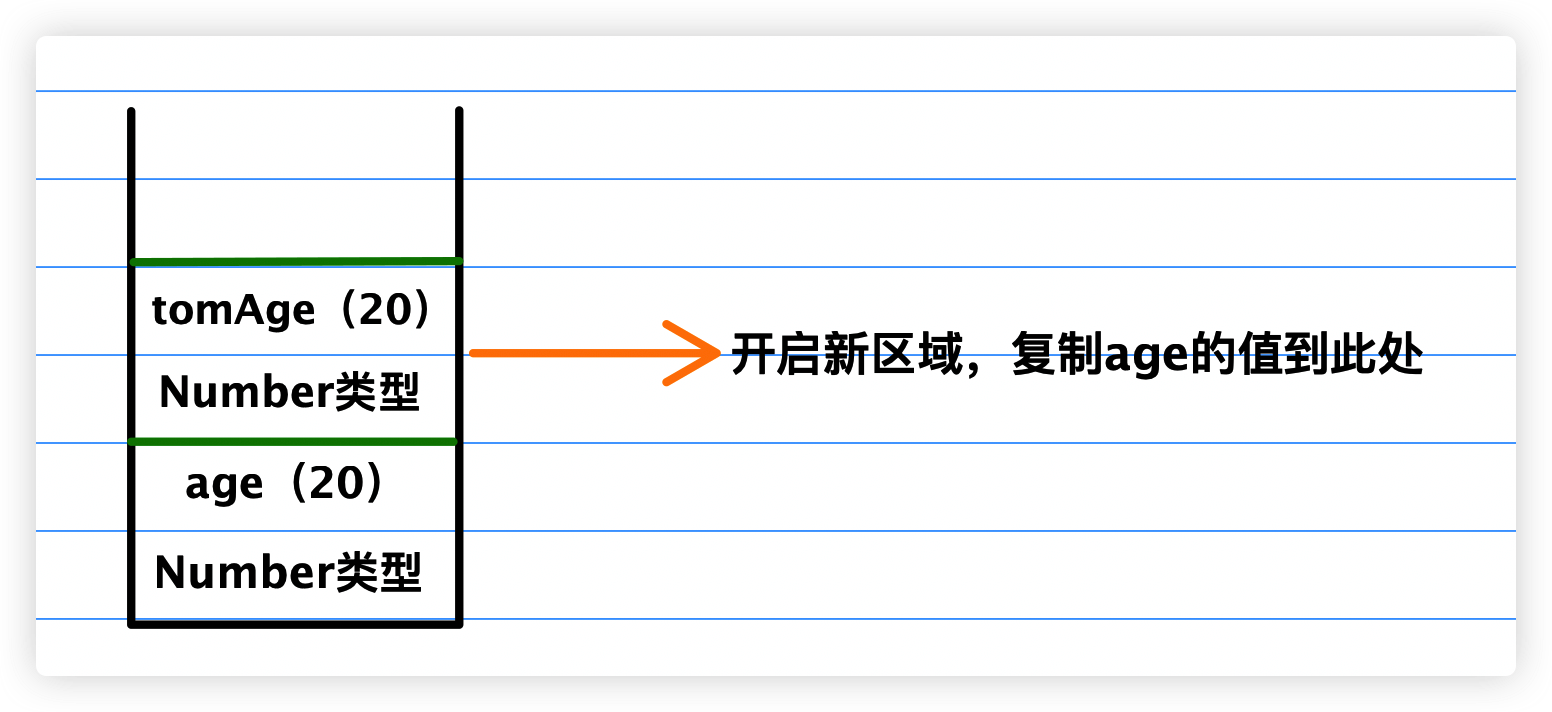
我们先来分析下上述例子中的age与tomAge,tomAge = age属于原始值复制,由于原始值是保存在栈内存的,所以它会在栈中新开启新区域,将age的值复制到新区域里,如下图所示:
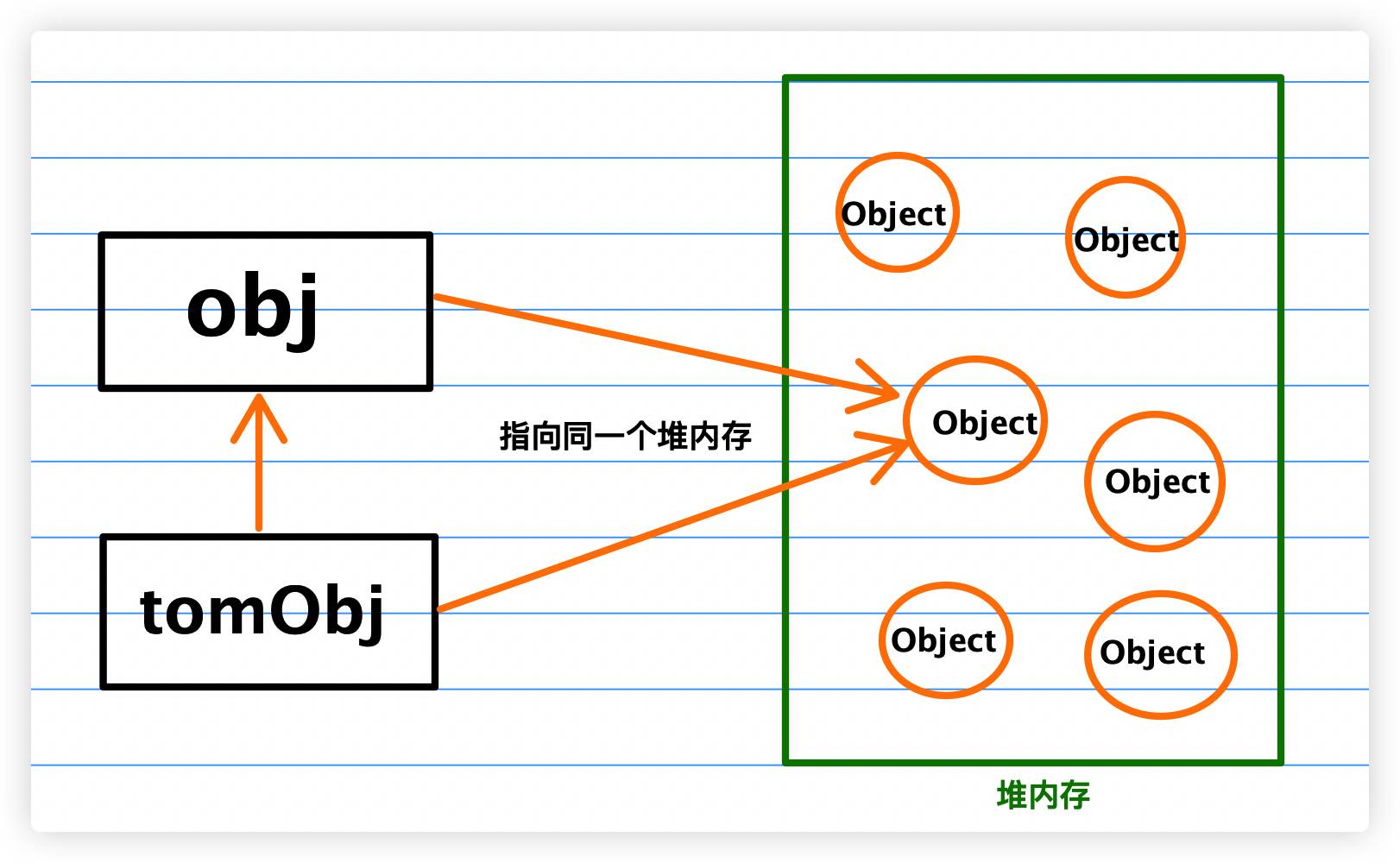
最后,我们来分析下上述例子中的obj与tomObj:
tomObj = obj属于引用值复制。- 引用值是保存在堆内存里的,因此它复制过来的是指针。
上述示例代码中,obj与tomObj都指向了堆内存中的同一个位置,tomObj的指针指向了obj,在深入理解原型链与继承 文章中,我们知道对象是拥有原型链的,因此当我们向obj中添加了name属性,tomObj也会包含这个属性。
接下来,我们画个图来描述下上述话语:
参数的传递
我们有了前两个章节的铺垫之后,接下来我们来分析下函数的参数是怎么传递的。
在JavaScript中所有函数的参数都是按值传递的,也就是说函数外的值会被复制到函数内部的参数中,这个复制机制与我们上个章节所讲一致。
- 按值传递参数时,值会被复制到一个局部变量,函数内部修改的是局部变量。
- 按引用传递参数时,值在内存中的位置会被保存在一个局部变量里。
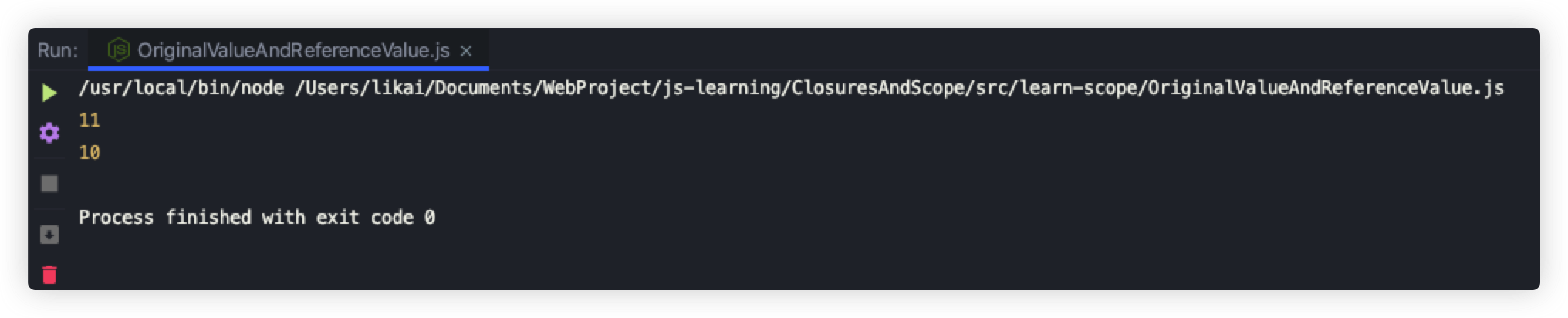
我们通过一个例子先来验证下按值传递参数的规则,如下所示:
function add(num) {
num++;
return num;
}
let count = 10;
const result = add(count);
console.log(result); // 11
console.log(count); // 10
上述代码中:
- 首先,我们创建了一个名为
add的函数,他接受一个参数num - 在函数内部,对参数进行自增,然后将其返回。
- 紧接着,我们声明了一个名为
count的变量并赋值为10。 - 调用
add函数,声明result变量来接收函数的返回值。 - 最后,打印result与count,结果分别为:
11、10
我们在在调用add函数时,传递了count参数进去,在函数内部处理时,它会把count的值复制一份到局部变量,在内部进行修改时,它改的就是复制过来的值,因此我们内部自增了num不会影响到函数外面的count变量。
运行结果如下:
接下来,我们通过一个例子验证下按引用传递参数的规则,如下所示:
function setAge(obj) {
obj.age = 10;
obj = {};
obj.name = "神奇的程序员";
return obj;
}
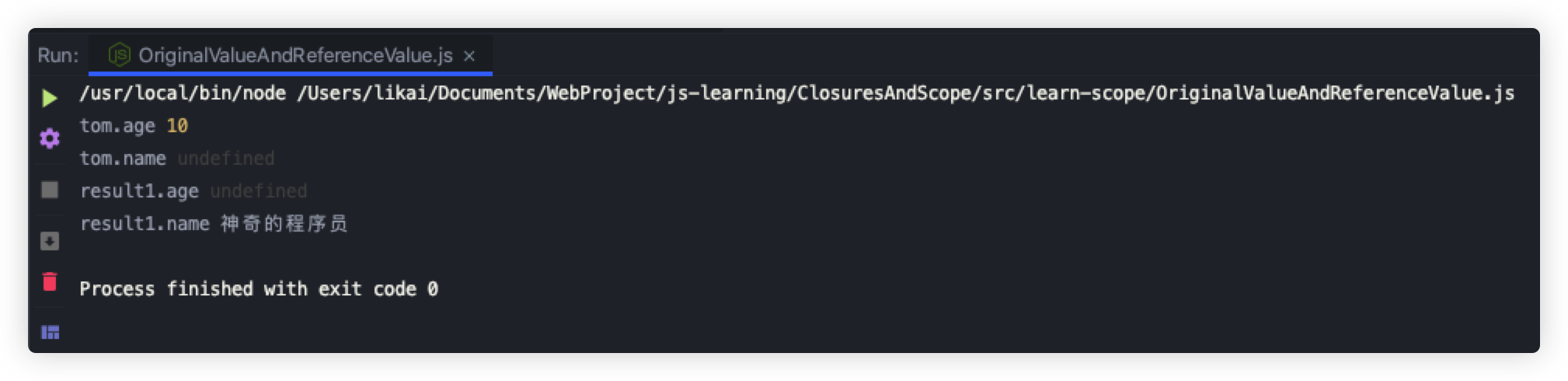
let tom = {};
const result1 = setAge(tom);
console.log("tom.age", tom.age); // 10
console.log("tom.name", tom.name); // undefined
console.log("result1.age", result1.age); // undefined
console.log("result1.name", result1.name); // 神奇的程序员
上述代码中:
- 我们创建了一个名为
setAge的函数,它接受一个对象 - 在函数内部,为参数对象新增了一个
age属性,将其赋值为10 - 随后,我们将参数对象赋值为一个空对象,又添加了一个name属性并赋值。
- 最后,返回参数对象。
- 紧接着,我们创建一个名为
tom的空对象 - 随后,将tom对象当作参数传给
setAge方法并调用,声明result1变量来接收其返回值 - 最后,我们打印
tom对象与result1对象的属性,执行结果符合按引用传递参数的规则
我们在调用setAge函数时,函数内部会把参数对象的引用拷贝一份到局部变量,此时参数对象的引用是指向函数外面的tom对象的,我们往参数对象中添加age属性,函数外面的tom对象也会被添加age属性。
当我们在函数内部将obj赋值为一个空对象时,局部变量的对象引用就指向了这个空对象,它与函数外面的tom对象也就断开了关联,所以我们添加了name属性,只会给新对象添加。
最后我们在函数内部返回的参数对象,它是指向一个新的地址的,自然就只有name属性。
所以,tom对象里只有age属性,result1对象里只有name属性。
运行结果如下:
执行上下文与作用域
了解完变量之后,接下来我们来学习下执行上下文。
执行上下文在JavaScript中是一个比较重要的概念,它采用栈作为数据结构,为了方便起见,本文简称它为上下文,它的规则如下:
- 变量或函数的上下文决定它们能访问哪些数据
- 每个上下文都会关联一个变量对象
- 这个上下文中定义的所有变量和函数都存在于变量对象上,无法通过代码访问
- 上下文在其所有代码都执行完毕后销毁
全局上下文
全局上下文指的就是最外层的上下文,它根据宿主环境决定,具体规则如下:
- 全局上下文在关闭网页或退出浏览器时销毁
- 全局上下文会根据不同的宿主环境变化,在浏览器中指的就是window对象
- 使用var定义的全局变量和函数都会出现在window对象上
- 使用let和const声明的全局变量与函数不会出现在window对象上
函数上下文
每个函数都有自己的上下文,接下来我们来看下函数的执行上下文规则:
- 函数开始执行时,它的上下文会被推入一个上下文栈中。
- 函数执行完成后,上下文栈会弹出该函数上下文。
- 将控制权归还给之前的执行上下文
- JS程序的执行流就是通过这个上下文栈来控制的
我们举个例子来说明下上下文栈:
function fun3() {
console.log('fun3')
}
function fun2() {
fun3();
}
function fun1() {
fun2();
}
fun1();
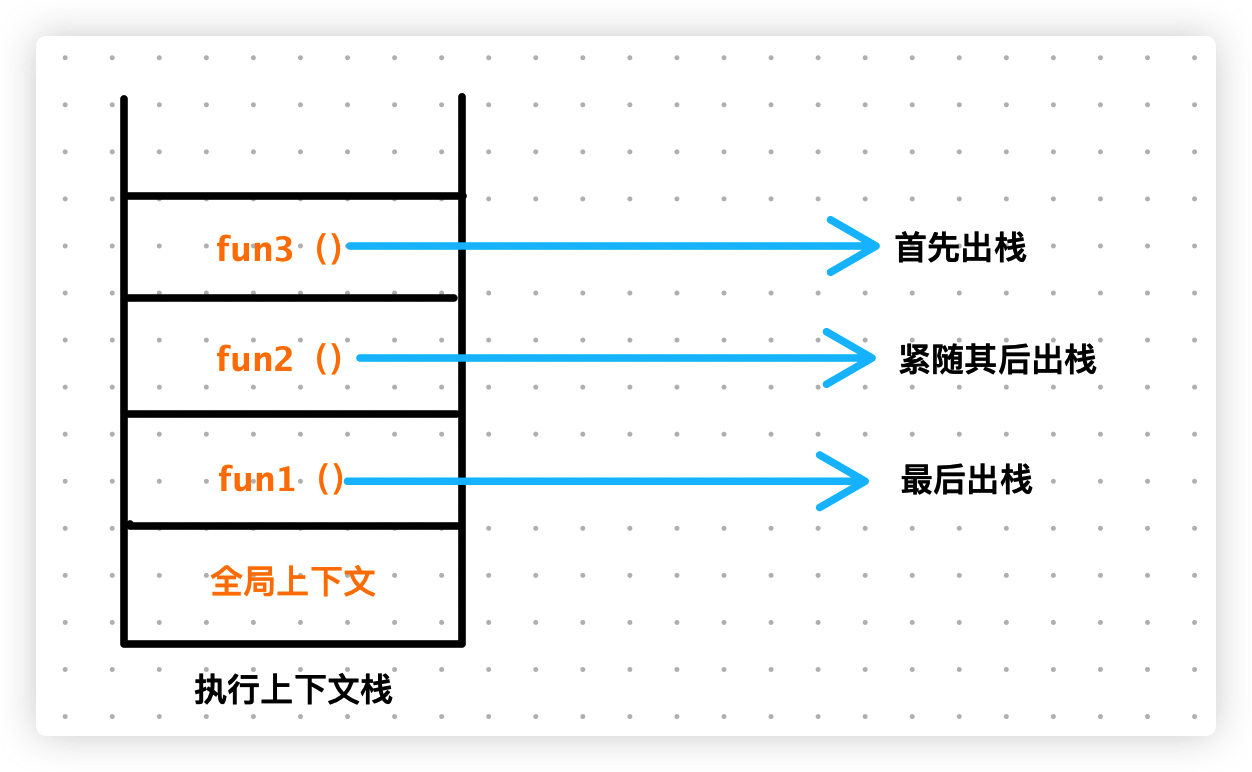
JavaScript开始解析代码时,最先遇到的是全局代码,所以在初始化的时候首先会往栈内压入一个全局执行上下文,整个应用程序结束时栈被清空。
当执行一个函数的时候,就会创建一个执行上下文,并且压入执行上下文栈,当函数执行完毕的时候,就会将函数的执行上下文从栈中弹出。
知道了上述概念后,我们回到上述代码中:
- 执行
fun1()函数时,会创建一个上下文,将其压入执行上下文栈 fun1函数内部又调用了fun2函数,因此创建fun2函数的上下文,将其压入上下文栈fun2函数内部又调用了fun3函数,因此创建fun3函数的上下文,将其压入上下文栈fun3函数执行完毕,出栈fun2函数执行完毕,出栈fun1函数执行完毕,出栈
我们画个图来理解下上述过程:
作用域与作用域链
我们了解完上下文之后,接下来就可以轻松的理解作用域了。
执行上下文代码时,当前上下文可以访问到的变量集合就是作用域。
上下文代码在执行的时候,会创建变量对象的一个作用域链,这个作用域链决定了各种上下文的代码在访问变量和函数时的顺序。
代码正在执行的上下文的变量对象,始终位于作用域链的最前端,如果上下文是函数,则其活动对象用作变量对象。
活动对象最初只有一个默认变量:arguments(全局上下文不存在),作用域链中的下一个变量对象来自包含上下文,再下一个对象来自再一个包含上下文。以此类推直至全局上下文。
全局上下文的变量对象,始终是作用域链的最后一个变量对象。
代码执行时的标识符解析是通过沿作用域链逐级搜索标识符名称完成的,搜索过程始终从作用链的最前端开始,逐级往后,直到找到标识符。(没找到标识符,则会报错)
接下来,我们通过一个例子来讲解下上述话语:
var name = "神奇的程序员";
function changeName() {
console.log(arguments);
name = "大白";
}
changeName();
console.log(name); // 大白
上述代码中:
- 函数
changeName的作用域链包含两个上下文对象:自身的函数上下文对象、全局上下文对象 arguments处在自身的变量对象中,name处在全局上下文的变量对象中- 我们可以在函数内部访问
arguments与name属性,就是因为可以通过作用域链找到它们。
执行结果如下:

接下来,我们举个例子来讲解下作用域链的查找过程:
var name = "神奇的程序员";
function changeName() {
let insideName = "大白";
function swapName() {
let tempName = insideName;
insideName = name;
name = tempName;
// 可以访问tempName、insideName、name
}
// 可以访问insideName、name
swapName();
}
// 可以访问name
changeName();
console.log(name);
上述代码:
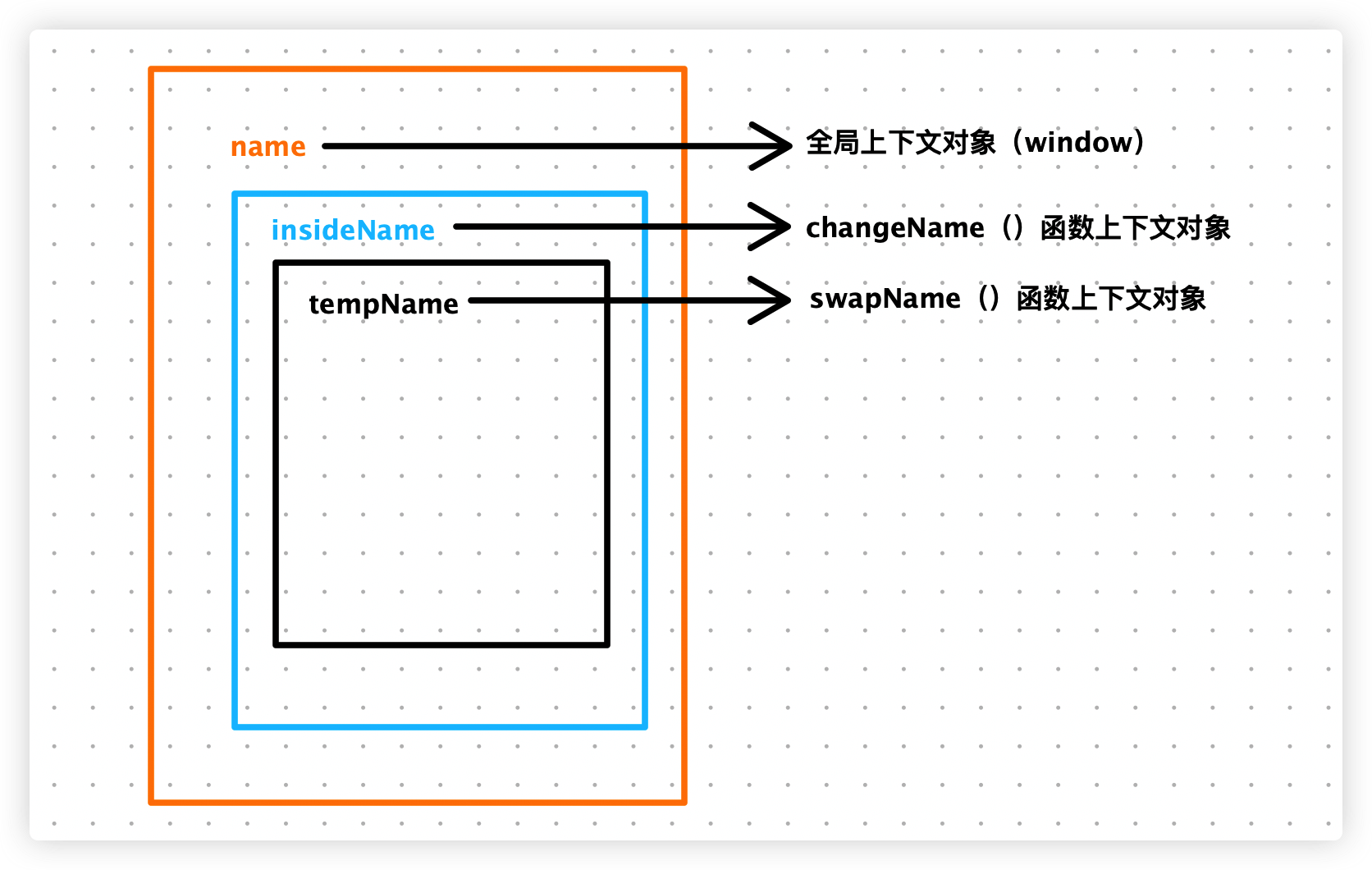
- 作用域链中包含三个上下文对象:
swapName函数的上下文对象、changeName函数的上下文对象、全局上下文对象 - 在
swapName函数内部,我们可以访问三个上下文对象中定义的所有变量。 - 在
changeName函数内部,我们可以访问它自身的上下文对象和全局上下文对象中定义的变量 - 在全局上下文中,我们就只能访问全局上下文中存在的变量。
通过上述例子的分析,我们知道了作用域链的查找是由内到外的,内部可以访问外部的变量,外部不可以访问内部的变量。
接下来,我们画个图来描述下上述例子的作用域链,如下所示:
注意⚠️:函数参数被认为是当前上下文中的变量,因此它也跟上下文中的其他变量遵循相同的访问规则。
变量作用域
在JavaScript中声明变量的关键字有:var、let、const,不同关键字声明出来的变量,作用域大不相同,接下来我们来逐步分析下它们的作用域。
函数作用域
使用var声明变量时,变量会被自动添加到最接近的上下文。在函数中,最接近的上下文就是函数的局部上下文。
如果变量未声明直接初始化,那么它就会自动添加到全局上下文。
我们举个例子来验证下上述话语:
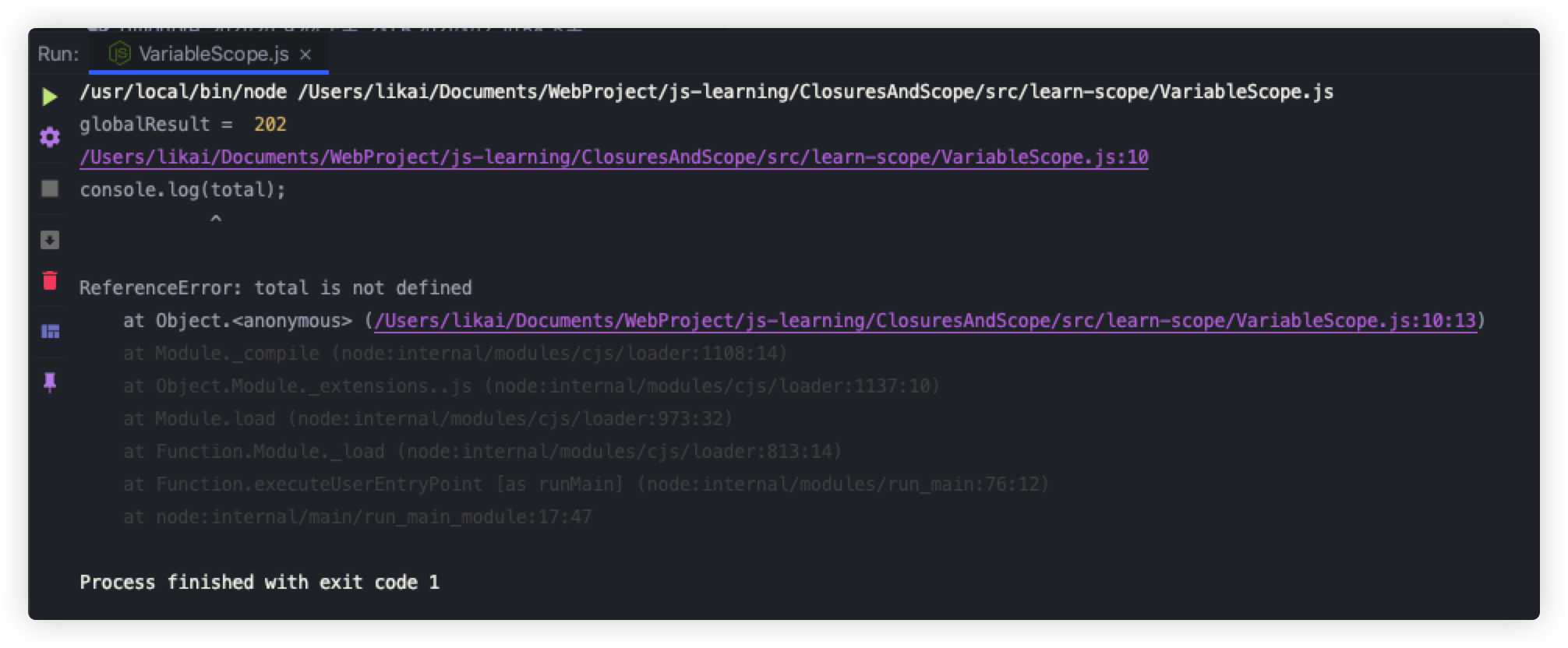
function getResult(readingVolume, likes) {
var total = readingVolume + likes;
globalResult = total;
return total;
}
let result = getResult(200, 2);
console.log("globalResult = ", globalResult); // 202
console.log(total); // ReferenceError: total is not defined
上述代码中:
- 我们声明了一个名为
getResult的函数,接受两个参数 - 函数内部使用
var声明了一个名为total的变量,并赋值为两个参数之和。 - 在函数内部,我们还直接初始化了一个名为
globalResult的变量,并赋值为total的变量值 - 最后,返回total的值。
我们调用getResult函数,传递参数200和2,随后,打印globalResult与total的值,我们发现globalResult的值正常打印出来了,total则会报错未定义,执行结果与上述话语完全吻合。
执行结果如下:
使用var声明会被拿到函数或全局作用域的顶部,位于作用域中所有代码之前,这个现象就叫变量提升。
变量提升会导致同一作用域的代码可以在声明前使用,我们举个例子来验证下,如下所示:
console.log(name);// undefined
var name = "神奇的程序员";
function getName() {
console.log(name); // undefined
var name = "大白";
return name;
}
getName();
上述代码:
- 我们先打印了name变量,然后才使用
var关键词进行了声明,打印的值为undefined - 随后,我们声明了一个名为
getName的函数,在函数内部先答应name变量,随后才声明,打印的值为getName - 最后,调用getName方法。
无论是在全局上下文还是函数上下文中,我们在声明前调用一个变量它的值为undefined,没有报错就证明了var声明变量会造成变量提升。
块级作用域
使用let关键字声明的变量,会有自己的作用域块,它的作用域是块级的,块级作用域由最近的一对的花括号{}届定。也就是说,if、while、for、function的块内部用let声明的变量,它的作用域都界定在{}内部,甚至单独的块,在其内部用let声明变量,它的作用域也是界定在{}内部。
我们举个例子来验证下:
let result = true;
if (result) {
let a;
}
console.log(a); // ReferenceError: a is not defined
while (result) {
let b;
result = false;
}
console.log(b); // ReferenceError: b is not defined
function foo() {
let c;
}
console.log(c); // ReferenceError: c is not defined
{
let d;
}
console.log(d); // ReferenceError: a is not defined
上述代码中,我们在if、while、function、以及单独的{}内都声明了变量,在块外部调用其内部的变量时都会报错ReferenceError: xx is not defined,除function外,如果我们在块内部使用var关键字去声明,那么在块外部就能正常访问到块内部的变量。
运行结果如下:
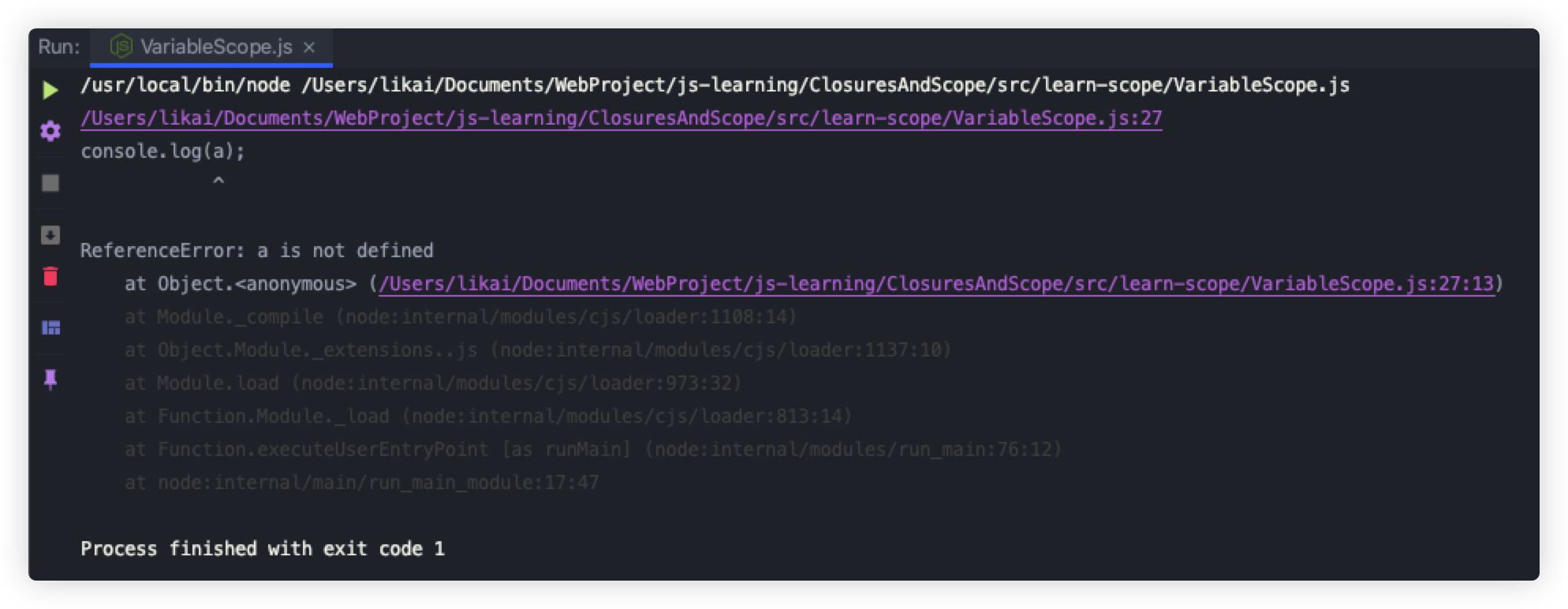
使用let声明变量时,同一个作用域内不能重复声明,如果重复则抛出SyntaxError错误。
我们举个例子来验证下:
let a = 10;
let a = 11;
console.log(a); // SyntaxError: Identifier 'a' has already been declared
var b = 10;
var b = 11;
console.log(b); // 11
上述代码中:
- 我们使用let重复声明了两个同名变量
a - 我们使用var重复声明了两个同名变量
b
我们在打印a时,会报错SyntaxError: Identifier 'a' has already been declared
我们在打印b时,重复的var声明则会被忽略,哪个在后,结果就是哪个,所以值为11
注意⚠️:严格来讲,let声明的变量在运行时也会被提升,但是由于“暂时性死区”的缘故,实际上不能在声明之前使用let变量。因此从
JavaScript代码的角度来说,let的提升跟var是不一样的。
常量声明
使用const关键字声明的变量,必须赋予初始值,一经声明,在其生命周期的任何时候都不能再重新赋予新值。
我们举个例子来验证下:
const name = "神奇的程序员";
const obj = {};
obj.name = "神奇的程序员";
name = "大白";
obj = { name: "大白" };
上述代码中:
- 我们使用const声明了两个变量
name、obj - 为obj添加name属性,我们没有重新给obj赋值,因此它可以正常添加
- 紧接着,我们给name赋了新值,此时就会报错
TypeError: Assignment to constant variable. - 最后,我们给obj赋了新值,同样的也会报错。
运行结果如下:
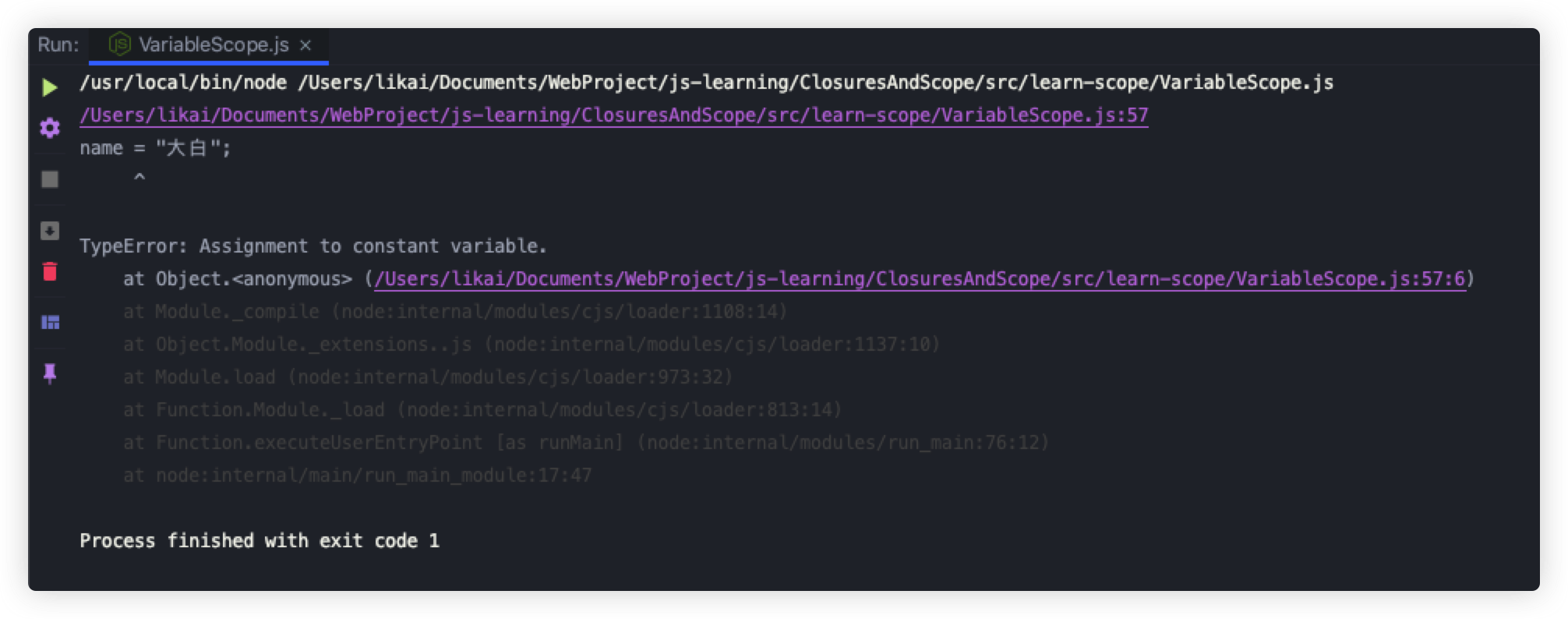
上述例子中使用const声明的obj可以修改它的属性,如果想让整个对象都不能修改,可以使用Object.freeze(),如下所示:
const obj1 = Object.freeze({ name: "大白" });
obj1.name = "神奇的程序员";
obj1.age = 20;
console.log(obj1.name);
console.log(obj1.age);
运行结果如下:
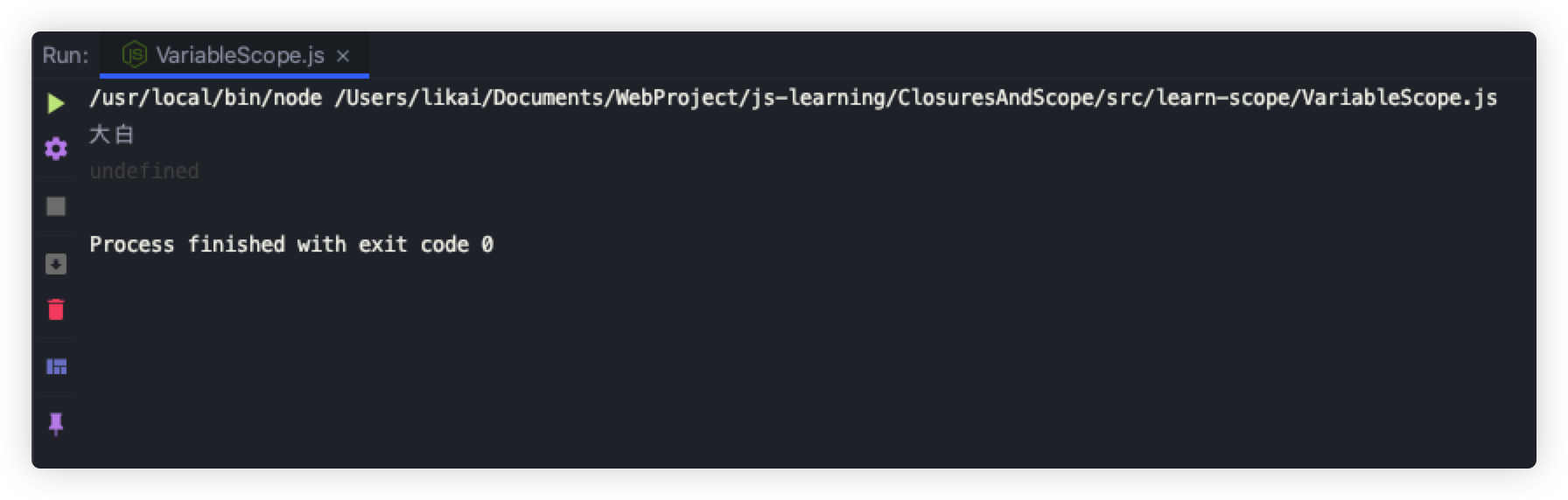
注意⚠️:由于const声明暗示变量的值是单一类型且不可修改,JavaScript运行时编译器可以将其所有实例都替换成实际的值,而不会通过查询表进行变量查找(V8引擎就执行这种优化)。
变量的生存周期
接下来,我们来看下变量的生命周期。
- 变量如果处在全局上下文中,如果我们不主动销毁,那么它的生存周期则是永久的。
- 变量如果处在函数上下文中,它会随着函数调用的结束而被销毁。
我们举个例子来说明下:
var a = 10;
function getName() {
var name = "神奇的程序员";
}
上述代码中:
- 变量
a处在全局上下文中,它的生存周期是永久的 - 变量
name处在函数上下文中,当getName执行完成后,name变量就会被销毁。
理解闭包
通过上述章节的分析,我们知道函数上下文中的变量会随着函数执行结束而销毁,如果我们通过某种方式让函数中的变量不让其随着函数执行结束而销毁,那么这种方式就称之为闭包 。
我们通过一个例子来讲解下:
var selfAdd = function() {
var a = 1;
return function() {
a++;
console.log(a);
};
};
const addFn = selfAdd();
addFn(); // 打印2
addFn(); // 打印3
addFn(); // 打印4
addFn(); // 打印5
上述代码中:
- 我们声明了一个名为
selfAdd的函数 - 函数内部定义了一个变量
a - 随后,在函数内部又返回了一个匿名函数的引用
- 在匿名函数内部,它可以访问到
selfAdd函数上下文中的变量 - 我们在调用
selfAdd()函数时,它返回匿名函数的引用 - 因为匿名函数在全局上下文中被继续引用,因此它就有了不被销毁的理由。
- 因此,这里就产生了一个闭包结构,
selfAdd函数上下文中的变量生命就被延续了
接下来,我们通过一个例子来讲解下闭包的作用:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>学习闭包</title>
<script type="text/javascript" src="js/index.js"></script>
</head>
<body>
<div>1</div>
<div>2</div>
<div>3</div>
<div>4</div>
<div>5</div>
</body>
</html>
window.onload = function() {
const divs = document.getElementsByTagName("div");
for (var i = 0; i < divs.length; i++) {
divs[i].onclick = function() {
alert(i);
};
}
};
上述代码中,我们获取了页面中的所有div标签,循环为每个标签绑定点击事件,由于点击事件是被异步触发的,当事件触发时,for循环早已结束,此时变量i的值已经是6,所以在div的点击事件函数中顺着作用域链从内到外查找变量i时,找到的值总是6。
我们的预想结果并非这样,此处我们可以借助闭包,把每次循环的i值都封闭起来,如下所示:
window.onload = function() {
const divs = document.getElementsByTagName("div");
for (var i = 0; i < divs.length; i++) {
(function(i) {
divs[i].onclick = function() {
alert(i);
};
})(i);
}
};
上述代码中:
- 在for循环内部,我们用了一个自执行函数,把每次循环的i值都封闭起来
- 当在事件函数中顺着作用域链查找变量i时,会先找到被封闭在闭包环境中的i
- 代码中有5个div,因此这里的i分别就是
0, 1, 2, 3, 4,符合了我们的预期
巧用块级作用域
在上述代码的for循环表达式中,使用var定义了变量i,我们在函数作用域章节讲过,使用var声明变量时,变量会被自动添加到最接近的上下文,此处变量i被提升到window.onload 函数的上下文中,因此当我们每次执行for循环时,i的值都会被覆盖,同步代码执行完后,异步代码执行时,获取到的值就是覆盖后的值。
我们除了使用闭包解决上述问题,还可以let来解决,代码如下所示:
window.onload = function() {
const divs = document.getElementsByTagName("div");
for (let i = 0; i < divs.length; i++) {
// let的隐藏作用域,可以理解成
// {let i = 0}
// {let i = 1}
// {let i = 2}
// {let i = 3}
// {let i = 4}
divs[i].onclick = function() {
alert(i);
};
}
};
上述代码的for循环表达式中,我们使用let声明了变量i,我们在块级作用域章节讲过,使用let关键字声明的变量,会有自己的作用域块,所以在for循环表达式中使用let等价于在代码块中使用let,因此:
for (let i = 0; i < divs.length; i++)这段代码的括号之间,有一个隐藏的作用域for (let i = 0; i < divs.length; i++) {循环体}在每次循环执行循环体之前,JS引擎会把i在循环体的上下文中重新声明并初始化一次
因为let在代码块中都有自己的作用域,所以在for循环中的表达式中使用let它的每一个值都会单独存在一个独立的作用域中不会被覆盖掉。
表层应用
接下来,我们通过几个例子来巩固下我们前面的所讲内容。
作用域提升
代码如下所示,我们在一个块内声明了一个函数foo(),初始化了一个foo变量,赋值为1。再次声明foo()函数,再次修改变量foo的值。
{
function foo() {
console.log(1111);
}
foo(); // 2222
foo = 1;
// 报错:此时foo的值已经是1了,而并非一个函数
// console.log(foo());
function foo() {
console.log(2222);
}
foo = 2;
console.log(foo); // 2
}
console.log(foo); // 1
上述代码中:
- 在块内部,函数
foo()声明了两次,由于JS引擎的默认行为函数会被提升,因此最终执行的是后者声明的函数 foo = 1属于直接初始化行为,它会自动添加到全局上下文。- 由于在块作用域内,
foo是一个函数,在执行foo = 1时会开始找作用域链,在块作用域内找到了foo,因此将它赋值为了1。 - 同样的,
foo = 2也会开始找作用域链,在块作用域内找到了foo,因此将它赋值为了2。
综合上述,在块内给foo赋值时,它都优先在块作用域内找到了这个变量对象,并没有改变全局上下文中的foo,因此块外的console.log(foo)的值仍然是块内部第一次初始化时变量提升时的值。
执行上下文栈
接下来我们举个例子来巩固下执行上下文栈的知识,代码如下所示:
var name = "神奇的程序员";
function changeName() {
var name = "大白";
function f() {
return name;
}
return f();
}
const result = changeName();
console.log(result);// 大白
var name = "神奇的程序员";
function changeName() {
var name = "大白";
function f() {
return name;
}
return f;
}
const result = changeName()();
console.log(result); // 大白
上述两段代码中,最后的执行结果都相同,不同之处在于:
- 第一段代码,
changeName()函数内部调用了f()函数并返回其执行结果 - 第二段代码,
changeName()函数内部直接返回了f函数的引用,形成了闭包结构。
它们在执行上下文栈的中的存储顺序也大不相同,我们先来分析下第一段代码:
- 执行
changeName()函数时,创建一个执行上下文,并将其压入上下文栈 changeName()函数内部调用了f()函数,创建一个执行上下文,并将其压入上下文栈f()函数执行完毕,出栈changeName()函数执行完毕,出栈
我们画个图来讲解下上述过程,如下所示:
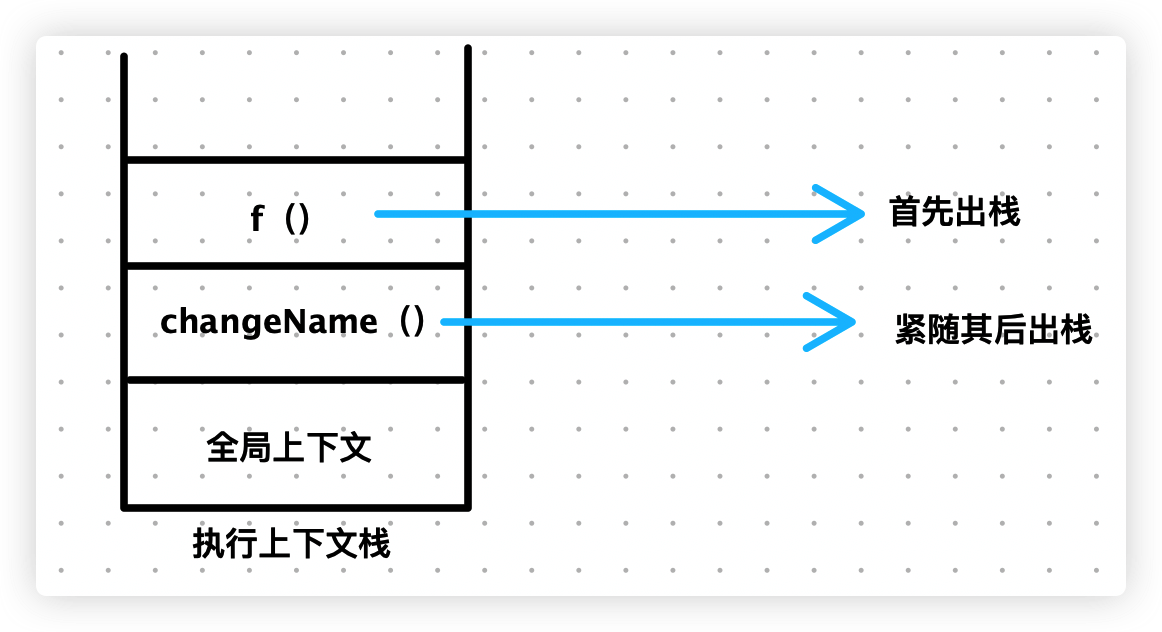
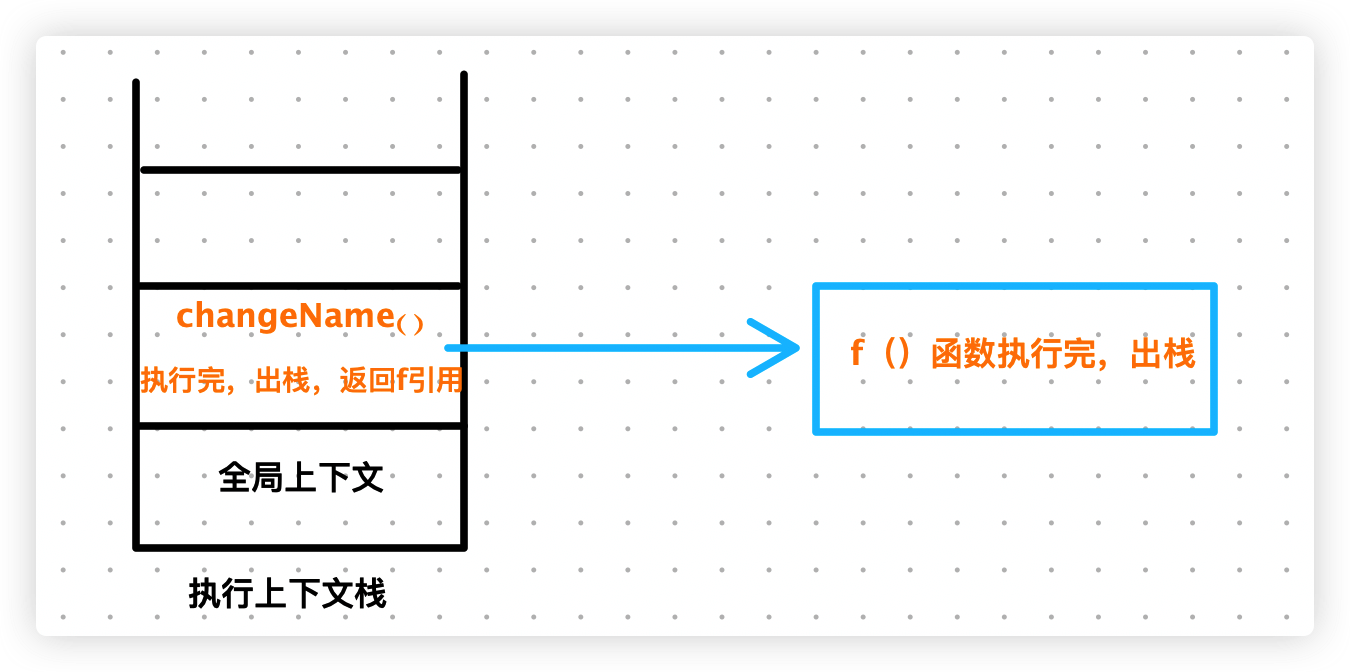
最后,我们分析下第二段代码:
- 执行
changeName()函数时,创建一个执行上下文,并将其压入上下文栈 changeName()函数执行完毕,出栈,返回f()函数引用- 执行
f()函数时,创建一个执行上下文,并将其压入上下文栈 f()函数执行完毕,出栈
我们画个图来讲解下上述过程,如下所示:
函数柯里化
函数柯里化是一种思想,它会把函数的结果缓存起来,它属于闭包的一种应用。
我们举个 未知参数求和 的例子来讲解下柯里化,代码如下所示:
function unknownSum() {
// 存储每次函数调用时的参数
let arr = [];
const add = (...params) => {
// 拼接新参数
arr = arr.concat(params);
return add;
};
// 对参数进行求和
add.toString = function() {
let result = 0;
// 对arr中的元素进行求和
for (let i = 0; i < arr.length; i++) {
result += arr[i];
}
return result + "";
};
return add;
}
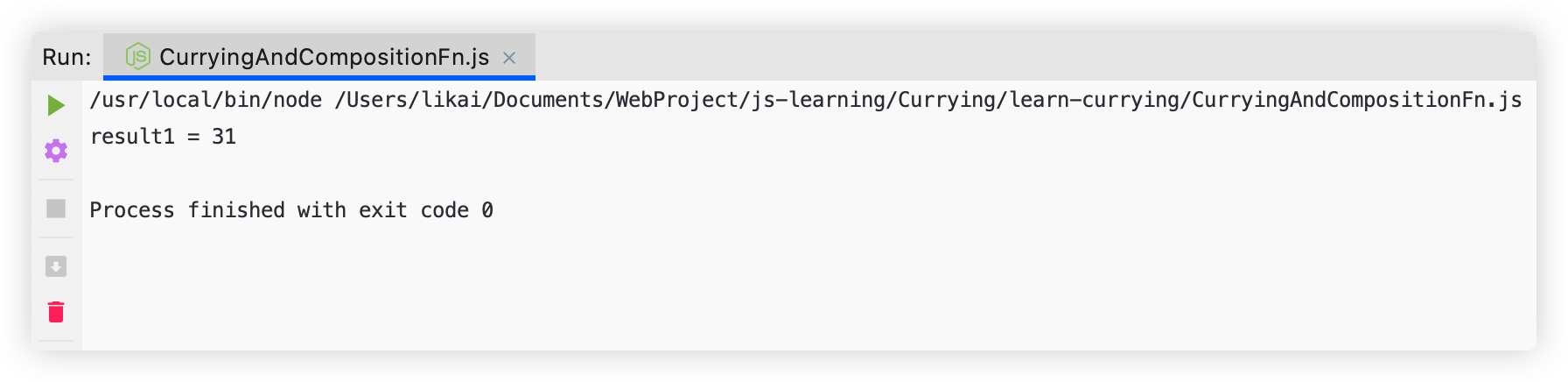
const result1 = unknownSum()(1, 6, 7, 8)(2)(3)(4);
console.log("result1 =", result1.toString());
未知参数求和:函数可以无限次调用,每次调用的参数都不固定。
上述代码中:
- 我们声明了名为
unknownSum()的函数 - 函数内部声明了
arr数组,用于保存每次传进来的参数 - 函数内部实现了一个
add函数,用于将传进来的参数数组传递拼接到arr数组 - 函数内部重写了
add函数的toString()方法,对arr数组进行了求和并返回结果 - 最后,在函数内部返回
add函数的引用,形成一个闭包结构
我们在调用unknownSum函数时,第一次调用()会返回add函数的引用,后续的调用()调用的都是add函数,参数传递给add函数后,由于闭包的缘故函数内部的arr变量并未销毁,因此add函数会把参数缓存到arr变量里。
最后调用add函数的toString方法,对arr内缓存的参数进行求和。
执行结果如下:
代码地址
本文为《JS原理学习》系列的第3篇文章,本系列的完整路线请移步:JS原理学习 (1) 》学习路线规划
本系列文章的所有示例代码,请移步:js-learning
写在最后
至此,文章就分享完毕了。
我是神奇的程序员,一位前端开发工程师。
如果你对我感兴趣,请移步我的个人网站,进一步了解。
- 文中如有错误,欢迎在评论区指正,如果这篇文章帮到了你,欢迎点赞和关注😊
- 本文首发于掘金,未经许可禁止转载💌
评论区